2011年春季学期
| 时间 | 星期三上午3-4节 |
| 地点 | B218 |
| 教师 | 罗迒哉 |
| 邮件 | hzluo (at) sei (dot) ecnu.edu.cn |
| 电话 | 62235089 |
| 办公室 | 数学馆东110 |
| 答疑(Office Hour) | 星期三8:00-10:00 |
课件 |
阅读材料 | 相关链接 |
|
教材:http://www-csli.stanford.edu/~hinrich/information-retrieval-book.html(请自行下载电子版)
英语分词(tokenize)的flex源程序:下载 可执行文件 编辑距离:http://www.merriampark.com/ld.htm Soundex:http://www.creativyst.com/Doc/Articles/SoundEx1/SoundEx1.htm Using Common Hypertext Links to Identify the Best Phrasal Description of Target Web Documents Introduction to Data Compression MPEG信息演示程序:下载 通过元数据特征提取照片语义的参考文献:
|
lyx: http://www.lyx.org |
1、URL归一化
通过网络爬虫可能会发现很多URL。理论上每个不同的URL应当指向不同的页面。但是,有相当一部分页面,它们可能有多个不同的URL。例如下面这两个URL就明显是同一个页面:
http://beta.thehindu.com/news/international/article110799.ece
http://beta.thehindu.com/news/international/article110799.ece?homepage=true
下面的两个URL也是指向同一个页面:
http://memcache.drivehq.com/
http://memcache.drivehq.com/home.htm
下面的两个URL又是另一种情况:
http://memcache.drivehq.com/
http://www.drivehq.com/web/memcache/
以上这些URL和页面不一一对应的问题可能在搜索引擎、网络数据挖掘等应用中产生不良影响,所以需要把这些指向同一页面但却不同的URL归一化成同一个。
2、适合存储海量小文件的文件系统
当系统中存储了太大数量的文件(例如:100万个以上的文件)后,系统的文件操作性能可能极大下降。设计一个文件系统,可以在存储了海量文件之后仍然保持较高的文件操作性能。
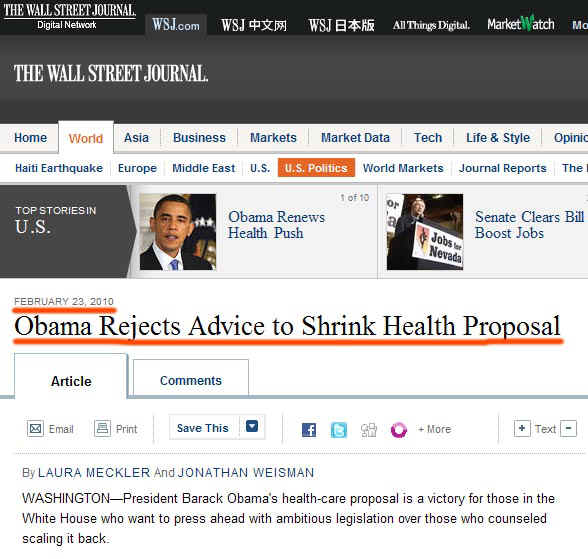
3、网页标题/发表时间提取
网页中一般都会标明发表时间和标题,如下图中红线所标出的。但是,这些信息往往和普通文字混淆,并没有特殊的HTML标记标出来。设计一个程序,可以通过解析HTML的各种标记,把其中表示发表时间和标题的文字提取出来
本课程使用Christopher D. Manning, Prabhakar Raghavan和Hinrich Schütze所著教材《Introduction to Information Retrieval》,部分幻灯片使用教材所附课件材料。


